GitHub 저장소: github.com/Jungle-12-303/week8_team6</a >
한 줄 요약: 지난주에 만든 SQL 처리기와 B+ Tree 인덱스를 내부 DB 엔진으로 재사용하고, 그 앞에 C 기반 HTTP API 서버와 Thread Pool을 붙여 외부 클라이언트가 SQL을 실행할 수 있게 만들었습니다.
왜 이 프로젝트가 특별했는가
정글에서 했던 여러 팀 프로젝트 중에서도 이번 프로젝트는 유독 오래 기억에 남습니다. 이유는 단순한 애착 때문만은 아닙니다. 3인 팀으로 역할을 나눠 구현한 결과물을 하나의 시스템으로 묶어내야 했고, 그 최종 구조와 선택의 이유를 제가 직접 발표해야 했기 때문입니다. 구현 단계에서는 각자 맡은 기능과 코드가 우선이었지만, 발표를 준비하는 순간부터는 HTTP 진입점, 요청 큐, 워커 스레드, DB API, SQL 엔진, 파일 기반 스토리지까지 전체 흐름을 하나의 설명 가능한 구조로 정리해야 했습니다.
그래서 이 프로젝트는 단순히 API 서버를 하나 더 붙인 경험이 아니라, 기존 SQL 처리기와 B+ Tree 인덱스를 손상시키지 않으면서도 외부 요청을 안정적으로 수용할 수 있는 계층을 설계한 경험으로 남았습니다. "이미 존재하는 엔진 위에 어떤 인터페이스와 동시성 모델을 얹을 것인가"를 끝까지 고민해야 했고, 그 과정에서 구현 능력뿐 아니라 설명 능력, 자료 구성 능력, 발표 전달력까지 함께 시험받았다는 점에서 특히 의미가 컸습니다.
발표 대본으로 다시 보는 프로젝트
발표 대본을 다시 꺼내 읽어보면, 첫 마디는 기능 소개가 아니라 "이번 주차의 핵심이 무엇이었는가"에 맞춰져 있었습니다.
"저희 팀 목표는 단순한 연결이 아니라, 기존 엔진을 훼손하지 않으면서도 안정적으로 외부 요청을 받을 수 있도록 HTTP API 서버, Thread Pool, 그리고 Mutex를 설계하고 구현하는 데 집중하는 것이었습니다."
실제로 발표를 준비하면서 제가 가장 많이 붙잡고 있었던 질문은 "우리가 정확히 무엇을 새로 만들었는가"보다도 "무엇을 재사용했고, 왜 그 위에 이런 계층을 덧씌웠는가"였습니다. 개발할 때는 일단 돌아가게 만드는 것이 먼저였지만, 발표 대본을 쓰는 순간부터는 accept 이후의 요청 흐름, Thread Pool의 역할, JSON 응답 책임 분리, 그리고 Mutex가 개입하는 정확한 지점</strong >까지 논리적으로 설명해야 했습니다. 그 덕분에 코드 조각 단위로 알고 있던 내용을 시스템 설계 단위로 다시 이해하게 됐고, 발표는 단순한 결과 공유가 아니라 구조를 재해석하는 과정이 됐습니다.
그림으로 짚어보는 시스템 구조 (발표 핵심 슬라이드)
전체 구조를 하나의 이야기로 묶기 위해, 발표에 사용했던 주요 시각 자료들을 토대로 프로젝트의 뼈대를 되짚어 봅니다.



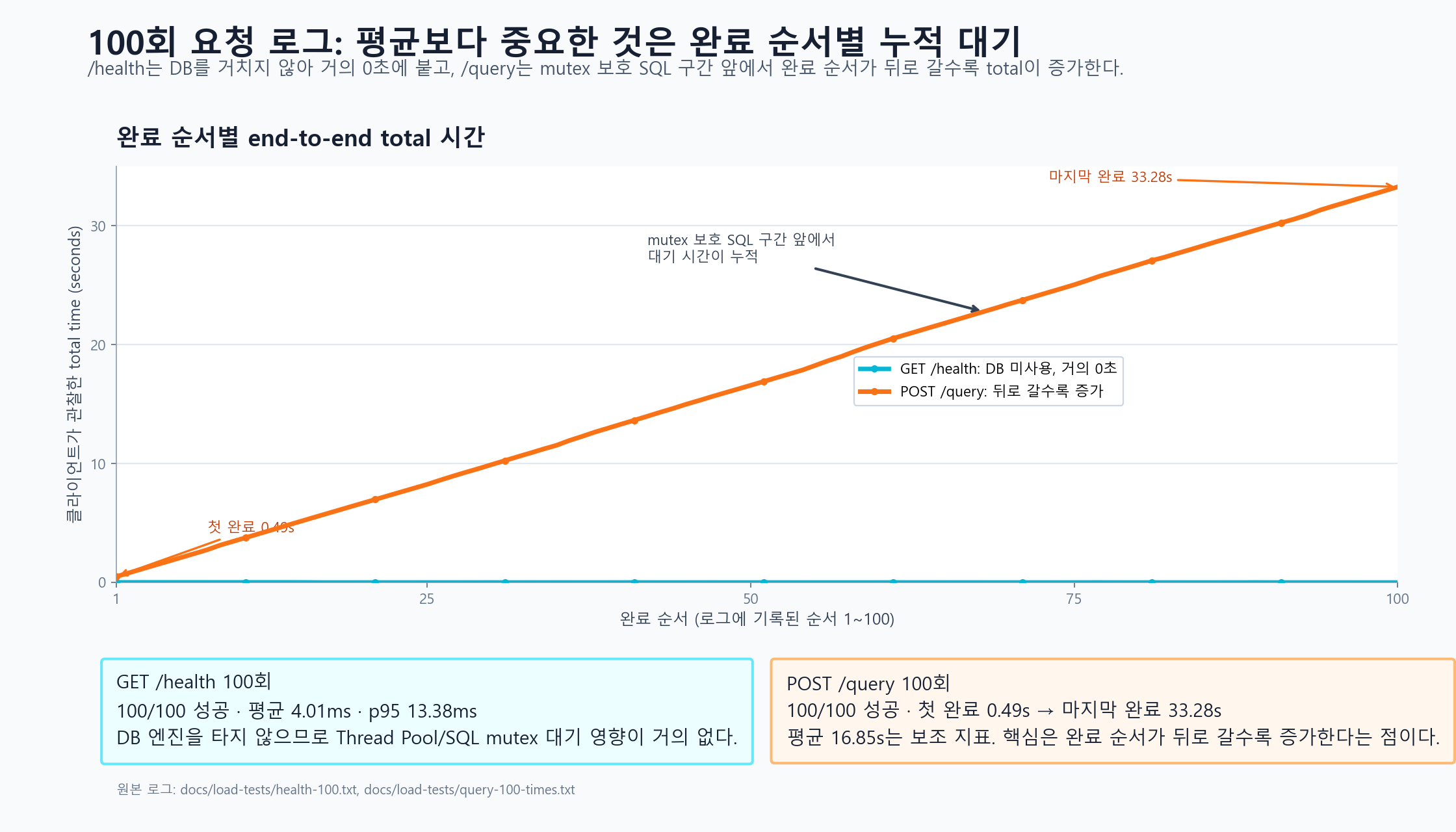
기술적으로 깊이 배운 점
가장 큰 수확은 단연 동시성 제어의 현실을 구현과 지표로 동시에 확인했다는 점입니다. 처음에는 Thread Pool을 붙이면 요청 처리량이 자연스럽게 올라갈 것이라고 막연히 생각했지만, 실제로는 기존 SQL 처리기와 파일 기반 B+ Tree가 스레드 안전하게 설계되어 있지 않았기 때문에 공유 파일과 인덱스 상태를 보호하는 장치가 먼저 필요했습니다. 특히 `users.tbl`, `users.idx` 같은 파일 기반 구조는 잘못 접근하면 오프셋과 인덱스 상태가 쉽게 꼬일 수 있어, 엔진 진입 구간 전체를 보수적으로 보호할 수밖에 없었습니다.
그 결과 얻은 결론은 명확했습니다. 요청 수용의 병렬성과 실제 DB 실행의 병렬성은 다른 문제라는 것입니다. API 서버는 여러 연결을 동시에 받고 큐에 쌓을 수 있었지만, SQL 실행 구간은 Mutex 때문에 직렬화됐고, 이는 곧 스레드 수를 늘려도 처리량이 비례해서 늘지 않는다는 뜻이었습니다. 발표를 준비하며 이 구조를 `/health`와 `/query`의 차이, backlog와 내부 queue의 분리, API 계층과 엔진 계층의 책임 구분까지 연결해서 설명할 수 있게 되면서, 이번 프로젝트는 단순한 구현 경험을 넘어 시스템 해석 능력을 키운 계기가 됐습니다.
또 하나 흥미로웠던 점은 B+ Tree 재사용의 의미였습니다. `WHERE id = ?` 조건에서는 인덱스를 통해 row offset을 바로 찾고, non-id 조건에서는 선형 탐색으로 내려가는 구조가 그대로 살아 있었기 때문에, API 서버를 붙인 뒤에도 내부 실행 경로의 차이가 응답 통계와 시연 포인트에 그대로 반영됐습니다. 덕분에 이번 프로젝트는 네트워크 서버를 만든 경험이면서 동시에, 기존 DB 엔진의 실행 계획과 저장 구조를 외부 인터페이스 관점에서 다시 이해한 경험이기도 했습니다.
구현한 것과 구현하지 않은 것
발표 피드백을 받고 나서 가장 먼저 든 생각은, 제가 만든 구조를 설명하는 데 집중한 나머지 무엇을 실제로 구현했고 무엇은 아직 구현하지 못했는지를 더 명확히 구분했어야 했다는 점이었습니다. 회고에서도 이 구분은 중요하다고 느껴, 아래처럼 정리해두는 편이 프로젝트의 현재 상태를 훨씬 정직하게 보여준다고 생각합니다.
구현한 것
- C 기반 HTTP API 서버에서 `/health`, `/query`, `/metrics` 요청 처리
- Thread Pool과 bounded queue를 사용한 요청 분배 구조
- 기존 SQL 처리기와 B+ Tree 인덱스를 재사용하는 DB API 계층
- `WHERE id = ?`에서 인덱스를 활용하고, non-id 조건은 선형 탐색으로 처리하는 실행 경로
- 부하 테스트 로그와 Python 기반 그래프를 이용한 병목 확인
구현하지 않은 것
- 엔진 내부의 세분화된 동시성 제어와 진짜 병렬 SQL 실행
- Read/Write Lock 분리, B+ Tree 노드 단위 락, lock coupling 같은 고도화
- 에러 상황별 세밀한 복구 전략과 운영 환경 수준의 보호 장치
- 그래프 지표 명칭과 시각 표현을 오해 없이 전달하는 발표용 데이터 설명 체계
이 구분을 해두고 보니 프로젝트의 강점도 더 선명해졌습니다. 우리는 API 서버와 요청 처리 구조를 실제로 동작하게 만들었고, 기존 엔진을 외부 인터페이스에 연결하는 데는 성공했습니다. 반면 고성능 DB 서버 수준의 세밀한 동시성 제어까지 갔다고 말할 수는 없었습니다. 즉, 이번 프로젝트는 "연결 구조를 설계하고 검증한 단계"로 보는 것이 가장 정확하다고 느꼈습니다.
발표 준비에서 투자한 소프트 스킬
이번에는 제가 직접 발표를 맡았기 때문에 구현만으로 끝내지 않고, 자료를 어떻게 더 설득력 있게 보여줄 것인가에도 꽤 많은 시간을 투자했습니다. 단순히 코드를 읽어주는 발표로 끝내고 싶지 않아서, 구조를 눈으로 이해할 수 있는 SVG 다이어그램과 시각 자료 정리에 신경을 썼고, 부하 테스트 결과 역시 숫자 나열로 끝내지 않고 Python 기반 시각화 도구로 그래프화해 전달력을 높이려 했습니다.
특히 Python으로 로그를 다시 가공해 그래프를 그리는 과정, SVG 형태의 구조도를 발표 흐름에 맞게 배치하는 과정은 제게 기술 외적인 역량을 많이 요구했습니다. 무슨 내용을 어떤 순서로 보여줘야 청중이 따라올 수 있는지, 어떤 그림이 추상적인 구조를 가장 빠르게 이해시키는지 계속 고민하게 됐고, 그 과정에서 발표력뿐 아니라 자료 해석력, 시각화 감각, 설명 설계 능력도 이전보다 분명히 좋아졌다고 느꼈습니다.
구현만 잘하는 것과, 구현한 내용을 다른 사람이 바로 이해할 수 있게 재구성하는 것은 전혀 다른 역량이었습니다. 이번 발표를 준비하면서 저는 코드뿐 아니라 시각 자료와 서사 구조까지 포함한 소프트 스킬에도 분명히 더 많이 투자했고, 그만큼 한 단계 정리된 방식으로 프로젝트를 바라보게 됐습니다.
아쉬웠던 점과 다음에 해보고 싶은 것
일정에 쫓겨 DB 엔진 전체를 커다란 Lock 하나로 감싼 점은 뚜렷한 한계이자 아쉬움입니다. 만약 시간이 더 주어졌다면 동시성 제어를 세분화하는 것뿐 아니라, 운영 중 실제로 마주칠 수 있는 엣지 케이스까지 더 집요하게 검증해보고 싶습니다.
- Read/Write Lock의 분리: `SELECT` 요청끼리는 서로 데이터를 변경하지 않으므로 동시에 접근하게 열어두고, `INSERT` 시에만 배타적 락을 걸었다면 처리량이 훨씬 개선되었을 것입니다.
- B+ Tree 노드 단위 락(Lock Coupling): 트리 전체를 잠그는 대신, 탐색하는 경로의 노드만 순차적으로 잠그고 푸는 방식을 적용해보고 싶습니다.
- 엣지 케이스 검증: malformed HTTP body, 비정상 종료 직전의 파일 쓰기, 중복 id INSERT, 내부 queue 포화, backlog 초과, non-id full scan이 몰리는 상황처럼 "평소엔 잘 보이지 않지만 실제 서비스에서는 자주 문제를 만드는 경우"를 따로 시나리오화해서 테스트해보고 싶습니다.
- 지표 표현 개선: 발표 자료에서 `total time` 같은 표현은 처리량과 지연시간을 혼동하게 만들 수 있으므로, 다음에는 latency, queue wait time, execution time을 가능한 한 분리해서 보여주고 싶습니다.
이번에 새롭게 공부한 backlog, 그리고 실제 개발에서의 활용
이번 프로젝트에서 개인적으로 가장 크게 남은 개념 중 하나는 backlog였습니다. 이전에는 막연히 "연결이 많이 오면 서버가 힘들어진다" 정도로만 생각했는데, 이번에는 `accept()` 이전에 커널이 연결을 어디까지 받아두는지, 그리고 그 이후 우리 프로그램의 내부 queue가 어떻게 이어받는지를 구조적으로 이해하게 됐습니다. 특히 backlog와 worker queue를 구분해서 보게 되면서, 병목이 생겼을 때 "네트워크 수용 단계가 문제인지", "애플리케이션 내부 처리 단계가 문제인지"를 나눠서 생각할 수 있게 된 점이 컸습니다.
이건 실제 개발에서도 꽤 직접적으로 활용될 수 있다고 느꼈습니다. 예를 들어 트래픽이 순간적으로 몰리는 API 서버를 운영할 때 backlog 크기와 worker 수, 내부 queue 정책, 타임아웃 정책을 같이 설계해야 갑작스러운 스파이크를 더 안정적으로 흡수할 수 있습니다. 반대로 backlog만 무작정 늘리면 요청을 "받아두기만" 하고 실제 처리는 못 해서 지연시간만 커질 수도 있으니, 결국 backlog는 성능 튜닝 값이 아니라 시스템이 어디까지 버티고 어디서부터 거절할지 정하는 보호 장치로 이해해야 한다고 느꼈습니다.
앞으로 비슷한 서버를 만들게 된다면 backlog를 단순한 소켓 옵션으로 넘기지 않고, 내부 queue 길이, worker 처리 속도, 에러 응답 전략과 함께 설계해보고 싶습니다. 결국 backlog를 이해했다는 것은 연결을 받는다는 행위를 단순한 네트워크 이벤트가 아니라, 서비스 전체의 수용력(capacity)과 사용자 지연 경험을 조절하는 지점으로 보기 시작했다는 뜻에 가깝습니다.
마치며
"우리는 기존 엔진 위에 API와 동시성 구조를 얹었고, 그 과정에서 시스템은 단순한 기능의 합이 아니라 구조와 제약으로 이해해야 한다는 걸 배웠습니다."
발표를 맡고 다시 정리해보니, 이 프로젝트의 핵심은 단순히 API를 붙였다는 사실보다 기존 DB 엔진 위에 새로운 계층을 안전하게 얹는 설계에 있었습니다. 3명의 팀원이 나눠 구현한 결과물은 `accept → queue → worker → db_api → SQL engine → JSON response`라는 흐름 안에서 하나로 연결되었고, 저는 발표 대본을 다듬는 과정에서 각 계층의 책임과 한계를 이전보다 훨씬 분명하게 설명할 수 있게 됐습니다.
동시에 이번 프로젝트는 제게 발표자의 시선이 얼마나 다른지 보여줬습니다. 구현자일 때는 기능 완성과 디버깅이 가장 중요했지만, 발표자일 때는 구조의 핵심을 압축하고, 그래프와 다이어그램을 근거로 선택의 이유를 전달해야 했습니다. 그래서 이 경험은 기술 구현의 회고이면서도, 복잡한 시스템을 이해 가능한 이야기로 바꾸는 연습에 가까웠습니다.
결국 이 프로젝트는 "무언가를 새로 만들었다"기보다, 재사용 가능한 엔진과 새로 추가한 인터페이스 사이의 긴장 관계를 어떻게 조율할 것인가</strong >, 그리고 그것을 어떻게 설득력 있게 설명할 것인가를 함께 배운 작업이었습니다. 그래서 저에게는 결과물 자체만큼이나, 그 결과를 구조적으로 말할 수 있게 된 경험이 더 크게 남았습니다.
이번 회고의 결론은 더 분명해졌습니다. 우리는 API 서버와 요청 처리 구조를 실제로 구현했고, 그 위에서 기존 SQL 처리기와 B+ Tree를 연결하는 데 성공했습니다. 하지만 세밀한 동시성 제어, 운영 환경 수준의 엣지 케이스 대응, 오해 없는 지표 표현까지 완성한 것은 아니었습니다. 그래서 이 프로젝트는 단순한 성공담이 아니라, 무엇을 구현했고 무엇이 아직 남아 있는지까지 포함해 시스템을 더 정확하게 이해하게 만든 기록</strong >으로 남았습니다.
'개발 > 프로젝트' 카테고리의 다른 글
| 운영체제 · Pintos · Project 1 Threads · 2편 (0) | 2026.04.29 |
|---|---|
| 운영체제 · Pintos · Project 1 Threads · 1편 (0) | 2026.04.29 |
| 크래프트 정글 × 바이브 프로젝트Mini SQL을 두 번 만들고 나서야보인 것들 (1) | 2026.04.16 |
| 크래프톤 정글 × 바이브 프로젝트Mini SQL을 두 번 만들고 나서야보인 것들 (1) | 2026.04.08 |
| 크래프톤 정글 × 수요코딩회Custom React 구현기 2편 — 과제 제약이 가르쳐준 React의 설계 원리 (0) | 2026.04.02 |